fuzz相关笔记整理
afl tips
fuzz_one ///测试用例变异过程
common_fuzz_stuff //变异完成后的通用步骤
write_to_testcase //将变异后的内容写入测试文件
run_target //运行目标进程
save_if_intersting //判断是否保存该测试用例
has_new_bits //判断该测试用例是否产生新状态
插桩模块: 普通模式, qemu模式, llvm模式
fuzz模块: 初始化, fuzzing策略, 语料库更迭
语料库及测试用例的最小化, 并行fuzz, 语法字典, 内存检测工具
代码插桩
1 | fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); |
在处理到某个分支时,需要插入桩代码,afl-as会生成一个随机数,作为运行时保存在ecx中的值. 便是用于标识这个代码块的key.
分支信息记录
在分支点注入的代码本质上相当于
1 | cur_location = ; |
在_afl_maybe_log()中可以看到其实现.
fuzz tips
AFL 未设计针对有特定状态机的复杂网络程序的fuzz, peach是更合适的选择.
使用AFL的tips:
1. 尽量使测试用例足够小, 规模往往和因fuzz而触发的错误存在相关性
2. 较小的文件会不仅可以减少测试和处理的时间,也能节约更多的内存,AFL给出的建议是最好小于1 KB,但其实可以根据自己测试的程序权衡,这在AFL文档的`perf_tips.txt`中有具体说明。
3. 确保测试对象足够简单(简单高效)
4. 只给需要测的库进行打桩汇编级别的插桩, 所以可以用未插桩的库替换掉被测程序中使用AFL编译器编译出来的库.
5. 并行, 因为afl-fuzz设计成只给工作进程分配一个核.gdb的栈回溯怎么看
gdb afl-case1 -ex “set args out/crashes/id:000001,sig:06,src:000003,op:havoc,rep:128”`
fuzz的一个关键点是创建好的测试用例,通过分析目标程序的所有潜在路径来最大化输入的覆盖率。
种子选择输入文件:
- 使用项目自身提供的测试用例
- 目标程序bug提交页面
- 使用格式转换器,用从现有的文件格式生成一些不容易找到的文件格式:
- afl源码的testcases目录下提供了一些测试用例
- 其他大型的语料库
- afl generated image test sets
- fuzzer-test-suite
- libav samples
- ffmpeg samples
- fuzzdata
- moonshine
afl-cmin 尝试找到与语料库全集具有相同覆盖范围的最小子集
afl-tmin 尝试减小单个输入文件的大小
在Fuzzing共享库时,将输入传递给要Fuzzing的库。这种情况下,可以通过设置LD_LIBRARY_PATH让程序加载经过AFL插桩的.so文件,不过最简单的方法是静态构建,通过以下方式实现:
1 | $ ./configure --disable-shared CC="afl-gcc" CXX="afl-g++" |
afl-showmap 跟踪单个输入的执行路径,并打印程序执行的输出,捕获的元组.
afl-fuzz并行Fuzzing,一般的做法是通过-M参数指定一个主Fuzzer(Master Fuzzer)、通过-S参数指定多个从Fuzzer(Slave Fuzzer)。 这两种类型的Fuzzer执行不同的Fuzzing策略,前者进行确定性测试(deterministic ),即对输入文件进行一些特殊而非随机的的变异;后者进行完全随机的变异。
多系统并行测试的一个脚本参考
1 | #!/bin/sh |
crash exploration mode
1 | $ afl-fuzz -m none -C -i poc -o peruvian-were-rabbit_out -- ~/src/LuPng/a.out @@ out.png |
afl-collect
基于exploitable来检查crashes的可利用性。它可以自动删除无效的crash样本、删除重复样本以及自动化样本分类。
1 | $ afl-collect -j 8 -d crashes.db -e gdb_script ./afl_sync_dir ./collection_dir -- /path/to/target --target-opts |
无论是GCC的GCOV还是LLVM的SanitizerCoverage,都提供函数(function)、基本块(basic-block)、边界(edge)三种级别的覆盖率检测
Address Sanitizer 如何使用
如何去分析crash
为了避免构建语法感知工具的麻烦,afl-fuzz提供了一种使用语言关键字,magic header或其他与目标数据类型相关联的特殊表示的可选字典为模糊过程提供种子的方法 - 并且使用它来重建底层语法
要使用这个功能,首先需要创建在dictionaries/README.dictionaries中讨论的两种格式之一的字典;然后在命令行中使用-x选项将fuzzer指向它。(在该目录的子目录下已经提供了几个常用字典)
没有办法提供更多结构化的底层语法的描述,但是fuzzer可能会根据单独的插桩反馈来找出其中的一些。 参考:
即使当没有给出明确的字典时,afl-fuzz将通过在确定性字节翻转期间非常仔细地观察插桩来尝试提取输入语料库中的现有语法表示(token-表示,记号)。 这适用于一些类型的解析器和语法,但不像-x模式那么好。 如果字典真的很难得到,另一个选择是让AFL运行一段时间,然后使用AFL自带的表示捕获库。 有关详细信息,请参阅libtokencap/README.tokencap。
基于覆盖的崩溃分组通常生成一个小数据集,可以手动或使用非常简单的GDB或Valgrind脚本快速分类。每个崩溃也可追溯到其在queue中的非崩溃的parent测试用例,从而更容易诊断故障。 崩溃探索模式,使用-C标志 .
在这种模式下,模糊器需要一个或多个崩溃的测试用例作为输入,并使用其反馈驱动的fuzzing策略来快速枚举程序中可以到达的所有代码路径,同时保持其处于崩溃状态。不导致崩溃的变异被拒绝; 任何不影响执行路径的更改也一样。输出是一个小文件库,可以快速检查攻击者对故障地址的控制程度,或者是否有可能通过一个初始的越界读取,以及查看下面的内容 。
由于有些内存访问错误并不一定会造成程序崩溃,如越界读,因此在没有开启ASAN的情况下,许多内存漏洞是无法被AFL发现的。所以,编译目标二进制代码时,开启ASAN,也是推荐的做法。对于使用afl-xxx编译来说,只需要设定环境变量AFL_USE_ASAN=1即可。 如果要使用ASAN,建议添加CFLAGS=-m32指定编译目标为32位;否则,很有可能因为64位消耗内存过多,程序崩溃。如果使用了ASAN,还需要注意为afl-fuzz通过选项-m 指定可使用的内存上限。一般对于启用了ASAN的32位程序,-m 1024即可。
AFL编译链接可执行文件和库文件时,建议使用static link(静态链接库,libxxx.a文件),当使用动态链接库时,将动态链接库(如当前目录)加到环境变量中:export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:.
clang 10中的SanitizerCoverage ,UndefinedBehaviorSanitizer
-fsanitize-coverage=trace-pc-guard 这一选项会使编译器在任一代码块边缘插入以下代码, 因为每条边缘都有自己的guard_variable(uint32_t)
1 | __sanitizer_cov_trace_pc_guard(&guard_variable) |
同时编译器还将插入对模块构造函数的调用
1 | // The guards are [start, stop). |
...=trace-pc,indirect-calls 选项会使在每个间接调用中插入
1 | __sanitizer_cov_trace_pc_indirect(void *callee) |
__sanitizer_cov_trace_pc_* 这些函数内部实现应该由用户定义, 它包含了对函数调用的检测和控制以及PC指针的控制权.
-fsanitize-coverage=inline-8bit-counters 类似trace-pc-guard但是替换了回调,而是放置了一个计数器.
-fsanitize-coverage = pc-table 编译器将创建一个已检测PC的表。 需要-fsanitize-coverage = inline-8bit计数器或-fsanitize-coverage = trace-pc-guard
统计代码覆盖率的两种情况:
有源码: SanitizerCoverage, 在编译选项中添加相应的覆盖率统计方式,比如基本块统计方式可以添加:
1
CFLAG=“-fsanitize=address -fsanitize-coverage=bb”
无源码: 使用Pin、DynamoRIO等二进制插桩工具去hook统计,或者pediy改指令的方式去监控也是可以的
How Much Test Coverage Is Enough For Your Testing Strategy?
插桩
源代码插桩和二进制插桩
简单来说就是依靠统计指令数量来推测每一步调用频率最高的指令, 类似bruteforce的思路.
1 | import sys |
Pin: 动态插桩. 支持插桩现实世界的应用, 支持插桩多线程应用, 支持信号量. 在指令代码层面实现编译优化. 用户可以用API编写由Pin调用的动态链接库形式的插件, 成为Pintool.
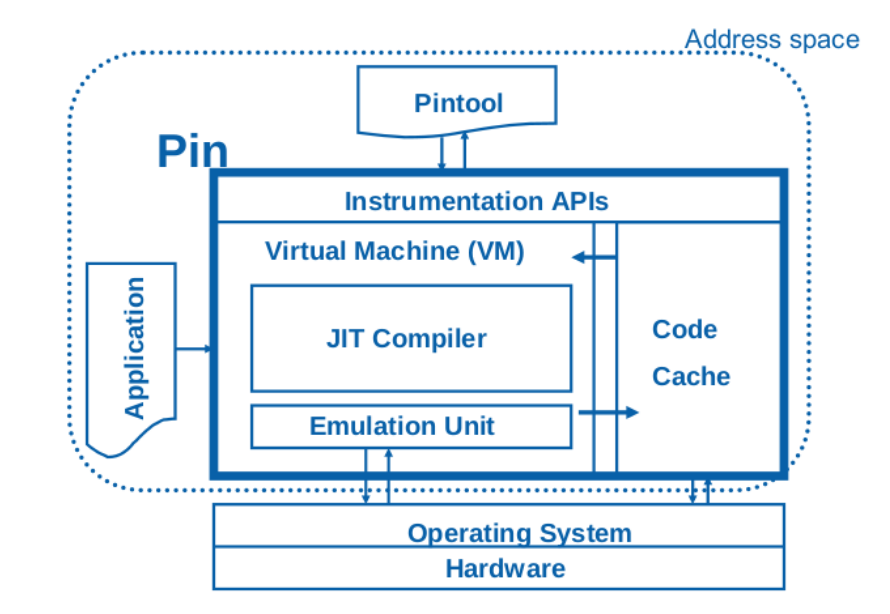
Pin 由进程级的虚拟机、代码缓存和提供给用户的插桩检测 API 组成。Pin 虚拟机包括 JIT(Just-In-Time) 编译器、模拟执行单元和代码调度三部分,当 Pin 将待插桩程序加载并获得控制权之后,在调度器的协调下,JIT 编译器负责对二进制文件中的指令进行插桩,动态编译后的代码即包含用户定义的插桩代码。编译后的代码保存在代码缓存中,经调度后交付运行。
程序运行时,Pin 会拦截可执行代码的第一条指令,并为后续指令序列生成新的代码,新代码的生成即按照用户定义的插桩规则在原始指令的前后加入用户代码,通过这些代码可以抛出运行时的各种信息。然后将控制权交给新生成的指令序列,并在虚拟机中运行。当程序进入到新的分支时,Pin 重新获得控制权并为新分支的指令序列生成新的代码。
通常插桩需要的两个组件都在Pintool中:
1. 插桩代码(instrumentation code), 在什么位置插入插桩
2. 代码分析代码(analysis code), 在选定的位置要执行的代码Pintool 采用向 Pin 注册插桩回调函数的方式,对每一个被插桩的代码段,Pin 调用相应的插桩回调函数,观察需要产生的代码,检查它的静态属性,并决定是否需要以及插入分析函数的位置。分析函数会得到插桩函数传入的寄存器状态、内存读写地址、指令对象、指令类型等参数。
- Instrumentation routines:仅当事件第一次发生时被调用
- Analysis routines:某对象每次被访问时都调用
- Callbacks:无论何时当特定事件发生时都调用
一般pintool的基本框架,在main函数中首先调用PIN_Init初始化,之后就可以使用INS_AddInstrumentFunction注册一个插桩函数,在原始程序的每条指令被执行前,都会进入Instruction这个函数中,其第2个参数为一个额外传递给Instruction的参数,即对应VOID *v这个参数,这里没有使用。而Instruction接受的第一个参数为INS结构,用来表示一条指令。
最后又注册了一个程序退出时的函数Fini,接着就可以使用PIN_StartProgram启动程序了
语法分析
畸形数据的生成基于合适的语法准则可以提高质量.